Java定时任务之xxl-job
一、简介
在Java中使用定时任务是一件很常见的事情,比如使用定时任务在什么时间,什么时候,去发布一些信息,或者去查询一些日志等相关的代码。这时,我们就要开发定时任务这中功能来实现此案例。XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
1.1 常见定时任务框架
若想持续(比如每分钟)采集股票数据,需要借助定时任务组件完成数据周期性采集工作,以下是常见的定时任务框架;
| 实现方式 | cron表达式 | 监控平台 | 任务告警 | 集群|分布式 | 开发难易程度 |
|---|---|---|---|---|---|
| JDK 的TimeTask | 不支持 | 无 | 无 | 不支持 | 复杂 |
| Spring Schedule | 支持 | 无 | 无 | 不支持 | 简单 |
| Quartz | 支持 | 无 | 无 | 不支持(需自行开发) | 复杂 |
| XXL-JOB | 支持 | 支持 | 支持 | 偏向集中式架构 | 相对简单 |
| Elastic-Job | 支持 | 支持 | 支持 | 偏向分布式架构 | 相对复杂 |
1.2 XXL-JOB特性
官方地址:http://www.xuxueli.com/xxl-job

1.3 整体架构
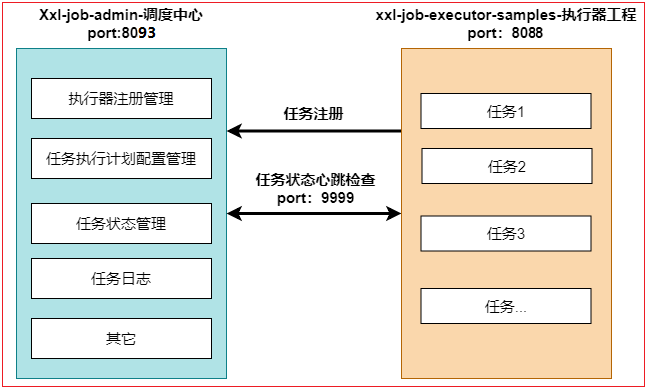
xxl-job共分为3大部分:任务调度器平台、任务执行器、任务处理器(jobHandler)、
任务调度器平台: 就是上述拉取下来的代码中的xxl-job-admin项目,这个项目就是任务调度平台。我们只需要配置一下就可以有自己的一个平台环境。而这个人任务调度器平台我们就可以理解为eureka(注册中心)
任务执行器:执行任务处理器
任务处理器(jobHandler):通过自己在项目中自定义不同的任务处理器来让任务执行器执行,并通过调度器平台 处理不同的任务。
二、XXL-JOB任务中心环境搭建
搭建步骤: XXL-JOB源码下载 --> 导入xxljob工程 --> 初始化数据库 --> 用docker安装或者更改原项目yml文件打包以jar包形式部署
2.1 环境搭建准备
- XXL-JOB源码下载:gitee下的开源地址下载
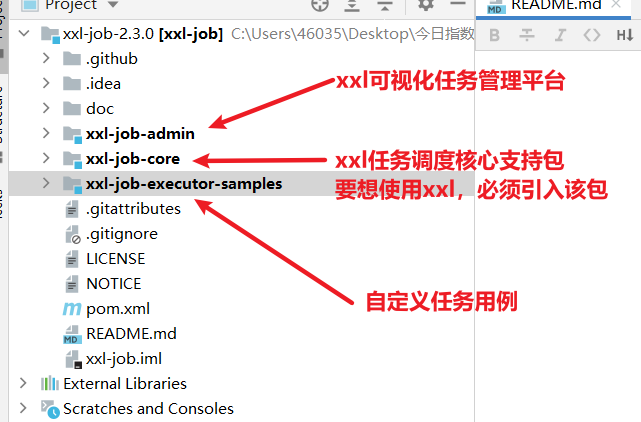
- 导入xxljob工程
- 初始化数据库: 文件doc --> db下面有sql文件直接导入即可(如果表xxl_job_registry导入过程报Specified key was too long; max key length is 767 bytes错误,则将i_g_k_v联合索引相关字段的varchar改小一些即可;)
2.2 环境部署
2.2.1 docker形式部署
- 拉取xxl-job-admin任务中心镜像:
docker pull xuxueli/xxl-job-admin:2.3.0
- 启动xxl-job任务中心容器:
# 在指定目录构建xxldata目录,然后运行如下docker指令:
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://主机:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=UTC --spring.datasource.username=root --spring.datasource.password=root" \
-p 8093:8080 \
-v $PWD/xxldata:/data/applogs \
--name=xxl-job-admin \
-d xuxueli/xxl-job-admin:2.3.0
- http://主机:8093/xxl-job-admin(默认账号:admin 密码:123456)
2.2.2 jar包形式部署
- 配置原文件yml文件:首先去xxl-job-admin找到配置文件,并修改port、mysql、mail、xxl.job.accessToken
- 修改port:默认8080可能会冲突建议修改
- mysql :改为自己MySQL信息
- mail:可以配置javamail配置为自己邮箱
- 修改 xxl.job.accessToken: 这个accessToken可以理解为秘钥,后面会在你自己的项目中配置和他名字一模一样的秘钥,让你的项目与任务调度器平台互相关联起来
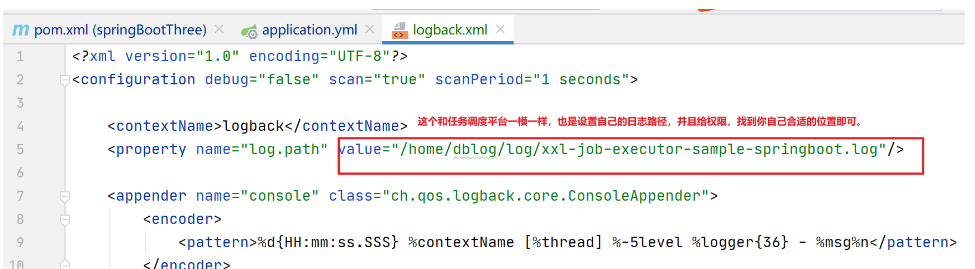
- 配置logback.xml:可以配置日志文件path,路径可以自定义,我就放到我习惯的位置,你也可以放到你自己习惯的位置
- 在linux中先创建好自己的路径日志,然后赋权限,文件赋权限的 :
chmod -R 777 /home/dblog/xxl-job/xxl-job-admin.log - 配置好之后,用idea打包,并将jar在linux中运行:
#将jar通过后台进程启动,并将启动信息指向xxl-job-admin.log中
nohup java -jar xxl-job-admin.jar > xxl-job-admin.log 2>&1 &
#查看日志
tail -f xxl-job-admin.log
- 访问地址:http://自己的ip:自己设置的端口号/xxl-job-admin (默认账号:admin 密码:123456)
三、 sprintboot引入xxl-job
3.1 引入xxl-job-core依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>
3.2 配置yaml
xxl:
job:
admin:
# 调度中心服务部署的地址(要和admin访问地址一致)
addresses: http://地址:端口号/xxl-job-admin
# 执行器通讯TOKEN,要和调度中心服务部署配置的accessToken一致,要不然无法连接注册
accessToken: default_token
executor:
# 执行器AppName
appname: job-demo
# 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
address:
ip: 填写自己服务器地址就行了
#执行器端口号(心跳检查接口):小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
port: 9999
# 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
logpath: /home/dblog/log/jobhandler
# 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
logretentiondays: 30
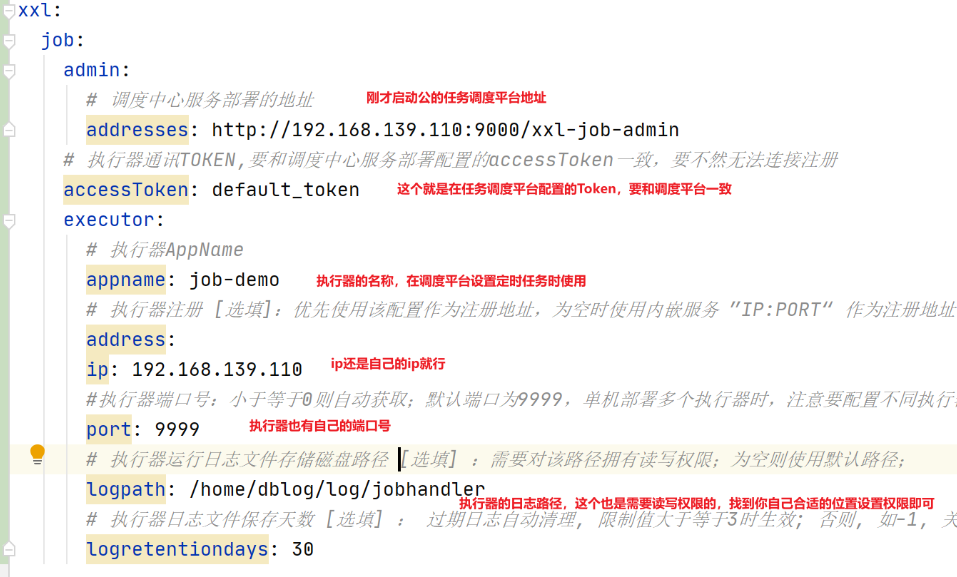
注意: logpath执行日志存储位置,也是需要自己在linux中创建的,和上述任务调度器平台创建一样,创建完成之后,设置权限。
3.3 配置日志
- 去你拉取的xxl-job项目中找到 logback.xml,复制到你自己项目的位置resources目录下
- 修改日志路径,在linux创建,并且给权限,这个就偷下懒不写了,在任务调度平台中已经写过了,可以模仿写一下
3.4 编写配置类
配置类代码,其实就是这个xxl-job项目中的XxlJobConfig 一模一样。
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
3.5 定义定时任务执行方法
将xxl-job中的SampleXxlJob复制到自己的项目中:
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
//todo 打印时间
System.out.println("hello xxljob.....");
}
//.....省略......
/**
* 5、生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public void demoJobHandler2() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
}
public void init(){
logger.info("init");
}
public void destroy(){
logger.info("destory");
}
}
@XxlJob中的value值就是定时任务的一个标识,注解作用的方法就是定时任务要执行逻辑的逻辑方法;
四、操作任务调度器平台(任务调度中心)
4.1配置任务执行器
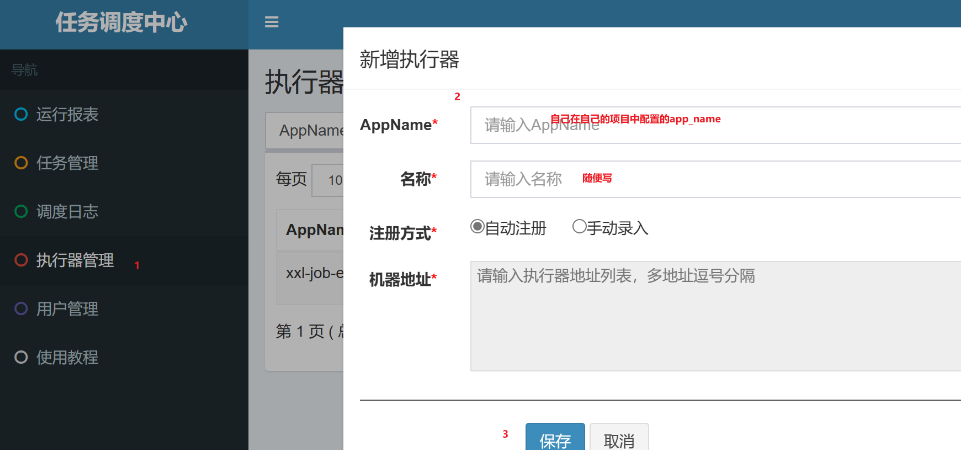
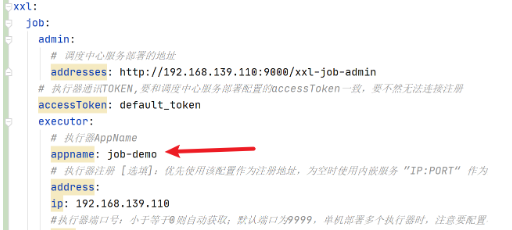
注意:自动注册,xxl-job会自动找到你的机器地址。
注意:如果自动注册不识别,可手动录入执行服务地址,格式比如:http://192.168.200.1:9999

4.2 配置任务执行计划
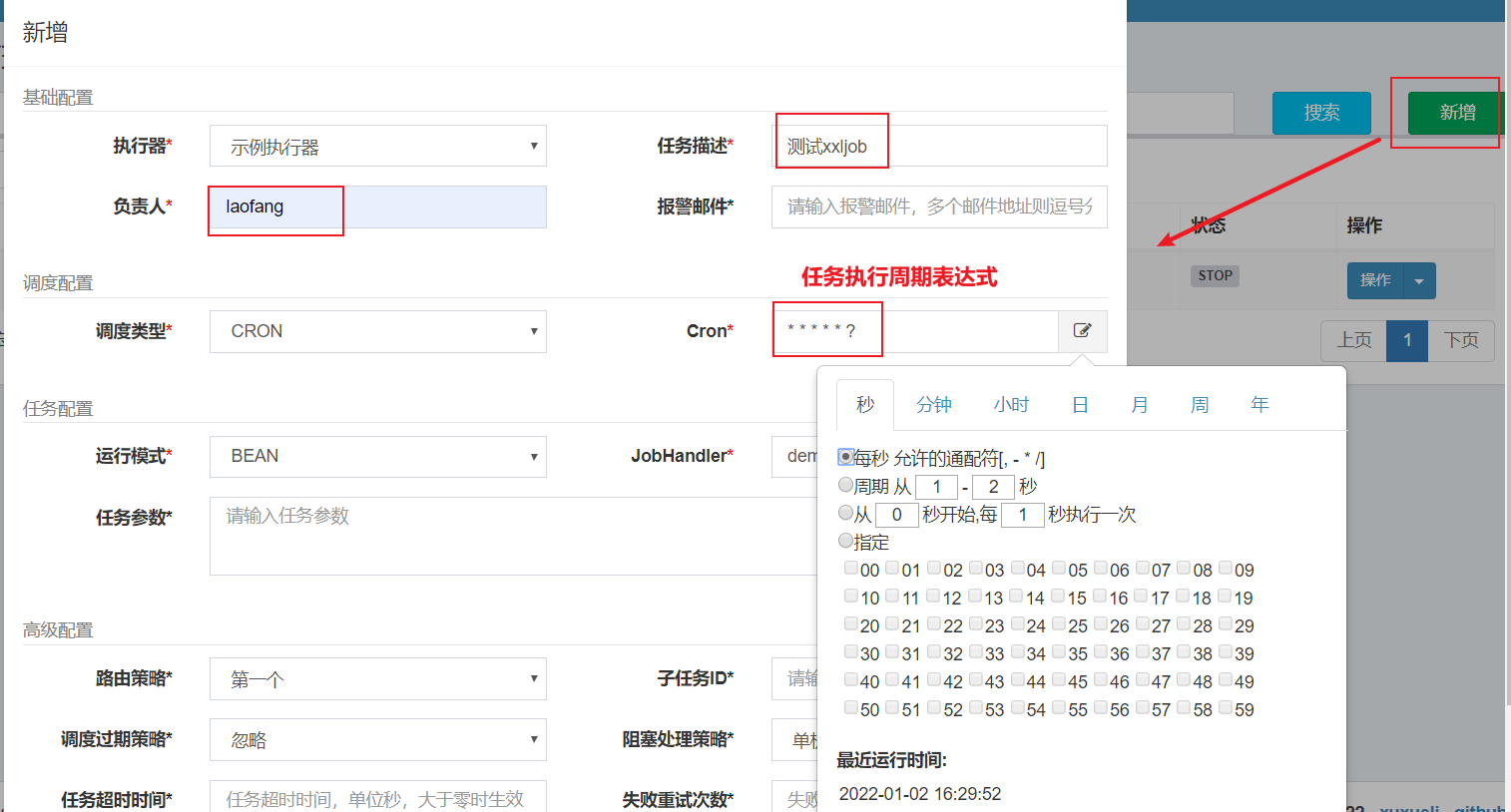
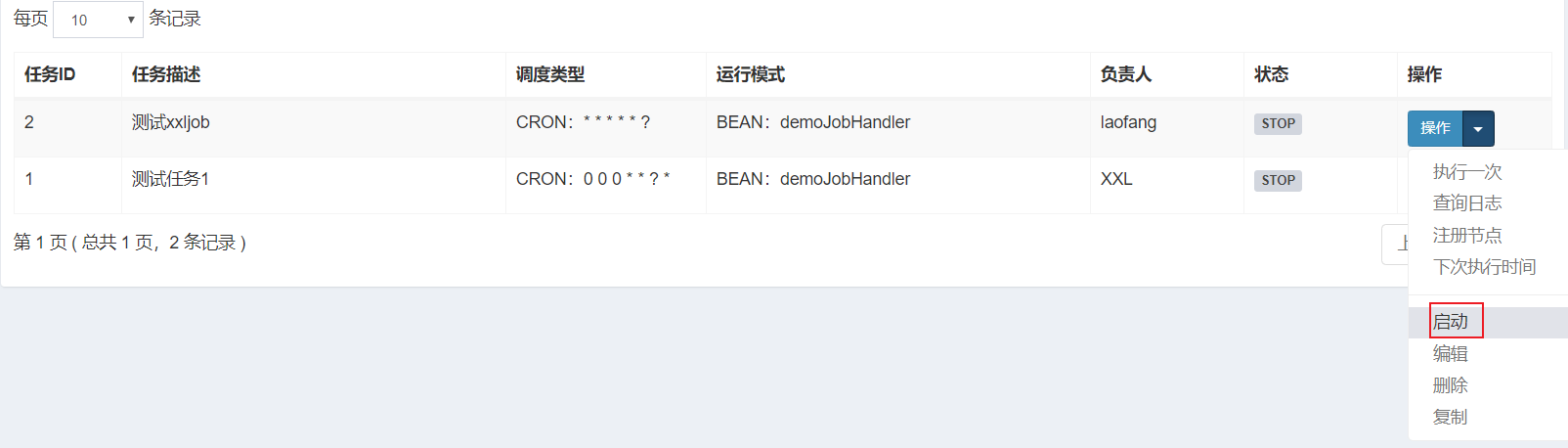
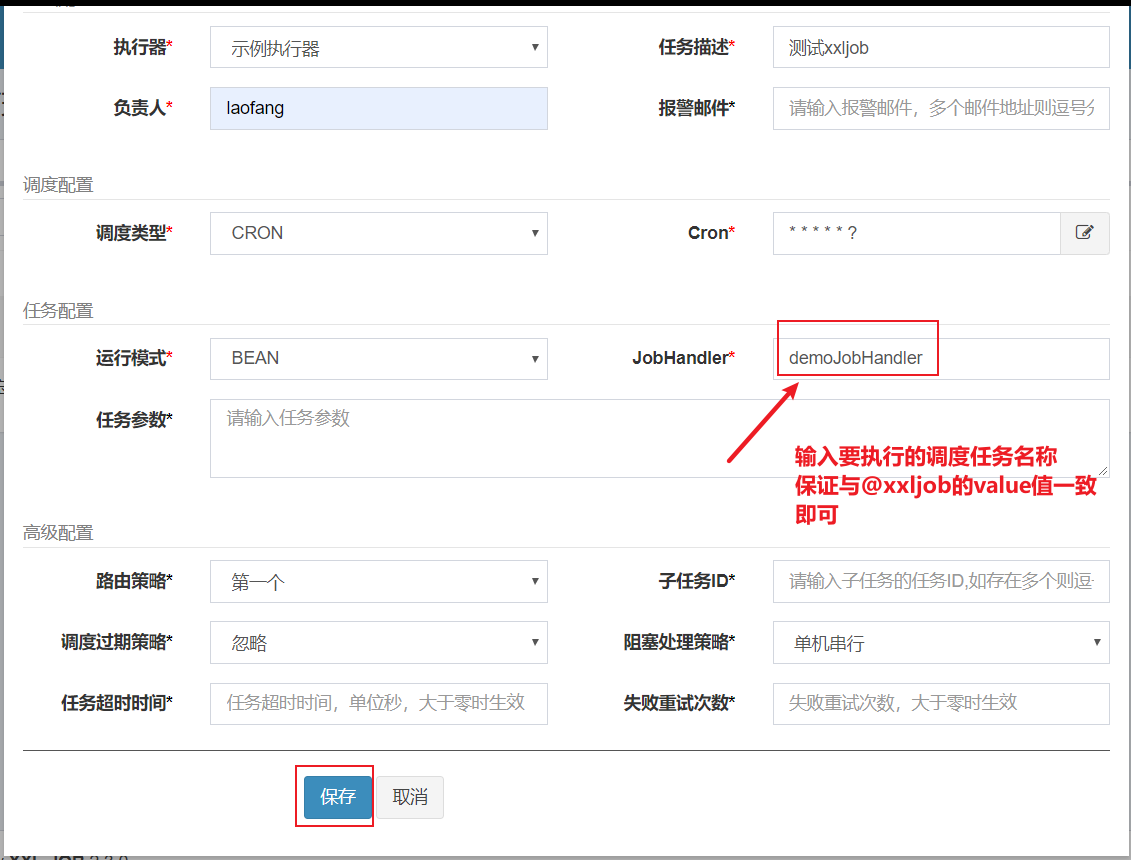
当然,我们也可以随时停止正在被执行的任务;
五、运行模式
5.1BEAN模式
Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法。
优点:每个任务只需要一个方法,添加@XxlJob注解即可,方便、快速。
缺点:需要Spring环境
5.2GLUE模式(Java)
GLUE模式(Java)
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。开发流程如下:
步骤一:调度中心,新建调度任务:
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 “GLUE模式(Java)”;
步骤二:开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。