Lambda,Stream,File使用
一、Lambda表达式
- lambda表达式可以理解为对匿名内部类的一种简化 , 但是本质是有区别的
- 面向对象思想 :
- 强调的是用对象去完成某些功能
- 函数式编程思想 :
- 强调的是结果 , 而不是怎么去做
1.1 体验Lambda表达式
public class LambdaDemo {
public static void main(String[] args) {
// 匿名内部类方式完成 传递的是对象
goSwimming(new Swimming() {
@Override
public void swim() {
System.out.println("铁汁 , 我们去游泳吧....");
}
});
// lambda表达式的方式完成 传递的是函数
goSwimming(() -> System.out.println("铁汁 , 我们去游泳吧...."));
}
public static void goSwimming(Swimming swimming) {
swimming.swim();
}
}
interface Swimming {
public abstract void swim();
}
1.2 函数式接口
- 只有一个抽象方法需要重写的接口,函数式接口。函数式接口是允许有其他的非抽象方法的存在例如静态方法,默认方法,私有方法。
- 为了标识接口是一个函数式接口,可以在接口之上加上一个注解: @FunctionalInterface 以示区别
- 在JDK中 java.util.function 包中的所有接口都是函数式接口。我们之前学习线程时学习的Runnable也是函数式接口
- 对于Java8中提供的这么多函数式接口,开发中常用的函数式接口有以下几个Predicate,Consumer,Function,Supplier`
- java8增加了很多函数式接口:
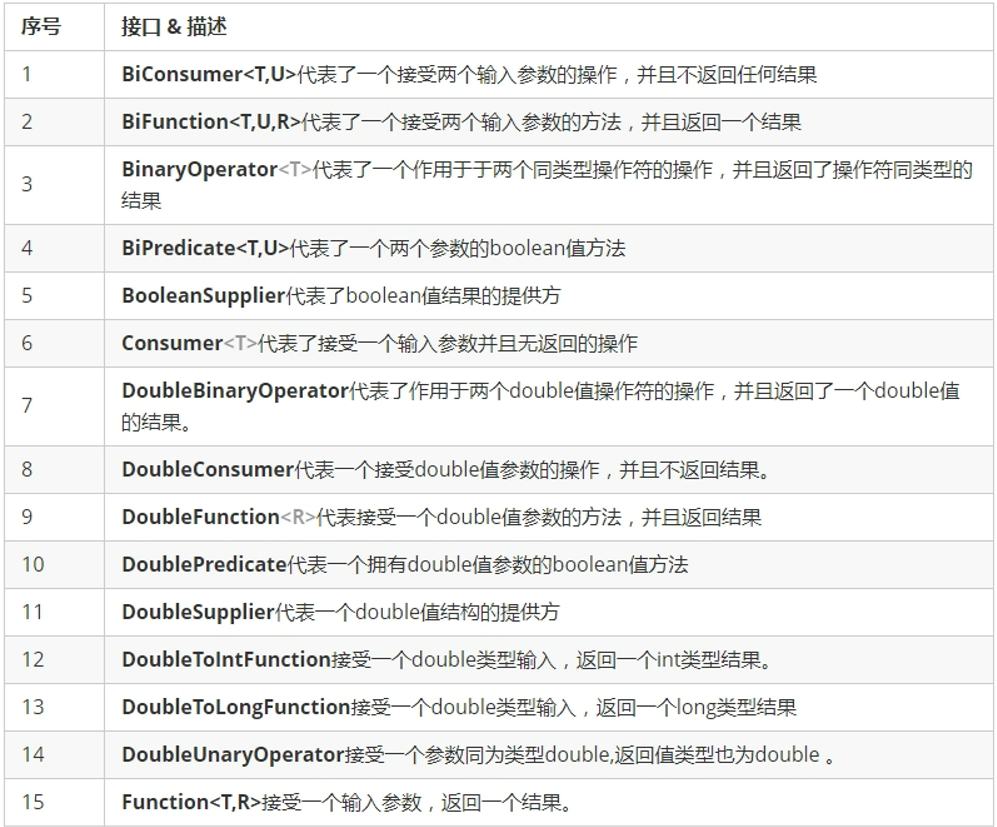
1.3 Lambda表达式的使用
-
使用前提
- 必须存在一个接口
- 接口中有且只有一个抽象方法
-
格式 : ( 形式参数 ) -> { 代码块 }
- 形式参数:如果有多个参数,参数之间用逗号隔开;如果没有参数,留空即可
- ->:由英文中画线和大于符号组成,固定写法。代表指向动作
- 代码块:是我们具体要做的事情,也就是以前我们写的方法体内容
1.4 Lambda表达式的案例
*
练习1:
1 编写一个接口(ShowHandler)
2 在该接口中存在一个抽象方法(show),该方法是无参数无返回值
3 在测试类(ShowHandlerDemo)中存在一个方法(useShowHandler)
方法的的参数是ShowHandler类型的,在方法内部调用了ShowHandler的show方法
*/
public class LambdaTest1 {
public static void main(String[] args) {
useShowHandler(() -> {
System.out.println("我是一个lambda表达式....");
});
}
public static void useShowHandler(ShowHandler showHandler) {
showHandler.show();
}
}
interface ShowHandler {
public abstract void show();
}
/*
1 首先存在一个接口(StringHandler)
2 在该接口中存在一个抽象方法(printMessage),该方法是有参数无返回值
3 在测试类(StringHandlerDemo)中存在一个方法(useStringHandler),
方法的的参数是StringHandler类型的,
在方法内部调用了StringHandler的printMessage方法
*/
public class LambdaTest2 {
public static void main(String[] args) {
useStringHandler((String msg) -> {
System.out.println(msg);
});
}
public static void useStringHandler(StringHandler stringHandler){
stringHandler.printMessage("今天天气不错 , 挺风和日丽的...");
}
}
@FunctionalInterface
interface StringHandler {
public abstract void printMessage(String msg);
}
二、Stream流★
重点代码:
stream().filter()//过滤
stream().map()//参数转换
stream().findFirst()//获取第一个参数
2.1 Stream的快速体验
/*
体验Stream流的好处
需求:按照下面的要求完成集合的创建和遍历
1 创建一个集合,存储多个字符串元素
"张无忌" , "张翠山" , "张三丰" , "谢广坤" , "赵四" , "刘能" , "小沈阳" , "张良"
2 把集合中所有以"张"开头的元素存储到一个新的集合
3 把"张"开头的集合中的长度为3的元素存储到一个新的集合
4 遍历上一步得到的集合
*/
public class StreamDemo {
public static void main(String[] args) {
// 传统方式完成
ArrayList<String> list = new ArrayList<>();
list.add("张无忌");
list.add("张翠山");
list.add("张三丰");
list.add("谢广坤");
list.add("赵四");
list.add("刘能");
list.add("小沈阳");
list.add("张良");
// 把集合中所有以"张"开头的元素存储到一个新的集合
ArrayList<String> list2 = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")) {
list2.add(s);
}
}
// 把"张"开头的集合中的长度为3的元素存储到一个新的集合
ArrayList<String> list3 = new ArrayList<>();
for (String s : list2) {
if (s.length() == 3) {
list3.add(s);
}
}
// 遍历list3集合
for (String s : list3) {
System.out.println(s);
}
System.out.println("================================");
// Stream流的方式
list.stream().filter(s -> s.startsWith("张") && s.length() == 3).forEach(s -> System.out.println(s));
}
}
2.2 Stream流的三类方法
- 获取Stream流
- 创建一条流水线,并把数据放到流水线上准备进行操作
- 中间方法
- 流水线上的操作。
- 一次操作完毕之后,还可以继续进行其他操作
- 终结方法
- 一个Stream流只能有一个终结方法
- 是流水线上的最后一个操作
2.3 第一类 : 获取方法
- 单列集合
- 可以使用Collection接口中的默认方法stream()生成流
default Stream<E> stream()
- 双列集合
- 双列集合不能直接获取 , 需要间接的生成流
- 可以先通过keySet或者entrySet获取一个Set集合,再获取Stream流
- 数组
- Arrays中的静态方法stream生成流
*/
- Arrays中的静态方法stream生成流
public class StreamDemo2 {
public static void main(String[] args) {
// 单列集合的获取
// method1();
// 双列集合的获取
// method2();
// 数组获取
// method3();
}
private static void method3() {
int[] arr = {1, 2, 3, 4, 5, 6};
Arrays.stream(arr).forEach(s -> System.out.println(s));
}
private static void method2() {
HashMap<String, String> hm = new HashMap<>();
hm.put("it001", "曹植");
hm.put("it002", "曹丕");
hm.put("it003", "曹熊");
hm.put("it004", "曹冲");
hm.put("it005", "曹昂");
// 获取map集合的健集合 , 在进行输出打印
hm.keySet().stream().forEach(s -> System.out.println(s));
// 获取map集合的entry对象 , 在输出打印
hm.entrySet().stream().forEach(s -> System.out.println(s));
}
private static void method1() {
// 可以使用Collection接口中的默认方法stream()生成流
ArrayList<String> list = new ArrayList<>();
list.add("迪丽热巴");
list.add("古力娜扎");
list.add("马尔扎哈");
list.add("欧阳娜娜");
list.stream().forEach(s -> System.out.println(s));
}
}
2.4 第二类 : 中间方法
Stream流中三类方法之一 : 中间方法
- Stream
filter(Predicate predicate):用于对流中的数据进行过滤 - Predicate接口中的方法 : boolean test(T t):对给定的参数进行判断,返回一个布尔值
- Stream
limit(long maxSize):截取指定参数个数的数据 - Stream
skip(long n):跳过指定参数个数的数据 - static
Stream concat(Stream a, Stream b):合并a和b两个流为一个流 - Stream
distinct():去除流中重复的元素。依赖(hashCode和equals方法) - Stream
sorted () : 将流中元素按照自然排序的规则排序 - Stream
sorted (Comparator<? super T> comparator) : 将流中元素按照自定义比较器规则排序
public class StreamDemo3 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张无忌");
list.add("张翠山");
list.add("张三丰");
list.add("谢广坤");
list.add("赵四");
list.add("刘能");
list.add("小沈阳");
list.add("张良");
list.add("张良");
list.add("张良");
list.add("张良");
// Stream<T> limit(long maxSize):截取指定参数个数的数据
// list.stream().limit(3).forEach(s -> System.out.println(s));
// Stream<T> skip(long n):跳过指定参数个数的数据
// list.stream().skip(3).forEach(s-> System.out.println(s));
// Stream<T> distinct():去除流中重复的元素。依赖(hashCode和equals方法)
// list.stream().distinct().forEach(s->{System.out.println(s);});
}
// // Stream<T> sorted (Comparator<? super T> comparator) : 将流中元素按照自定义比较器规则排序
private static void method3(ArrayList<String> list) {
list.stream().sorted(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
}).forEach(s->{
System.out.println(s);
});
}
// Stream<T> sorted () : 将流中元素按照自然排序的规则排序
private static void method3() {
ArrayList<Integer> list2 = new ArrayList<>();
list2.add(3);
list2.add(1);
list2.add(2);
list2.stream().sorted().forEach(s->{
System.out.println(s);
});
}
// // static <T> Stream<T> concat(Stream a, Stream b):合并a和b两个流为一个流
private static void method2(ArrayList<String> list) {
ArrayList<String> list2 = new ArrayList<>();
list2.add("迪丽热巴");
list2.add("古力娜扎");
list2.add("欧阳娜娜");
list2.add("马尔扎哈");
Stream.concat(list.stream(), list2.stream()).forEach(s -> {
System.out.println(s);
});
}
// Stream<T> filter(Predicate predicate):用于对流中的数据进行过滤
private static void method1(ArrayList<String> list) {
// filter方法会获取流中的每一个数据
// s就代表的是流中的每一个数据
// 如果返回值为true , 那么代表的是数据留下来
// 如果返回值的是false , 那么代表的是数据过滤掉
// list.stream().filter(new Predicate<String>() {
// @Override
// public boolean test(String s) {
// boolean result = s.startsWith("张");
// return result;
// }
// }).forEach(s -> System.out.println(s));
list.stream().filter(s ->
s.startsWith("张")
).forEach(s -> System.out.println(s));
}
}
2.5 第三类 : 终结方法
Stream流中三类方法之一 : 终结方法
- void forEach(Consumer action):对此流的每个元素执行操作
- Consumer接口中的方法 void accept(T t):对给定的参数执行此操作
- long count():返回此流中的元素数
public class StreamDemo4 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张无忌");
list.add("张翠山");
list.add("张三丰");
list.add("谢广坤");
// long count():返回此流中的元素数
long count = list.stream().count();
System.out.println(count);
}
// void forEach(Consumer action):对此流的每个元素执行操作
private static void method1(ArrayList<String> list) {
// 把list集合中的元素放在stream流中
// forEach方法会循环遍历流中的数据
// 并循环调用accept方法 , 把数据传给s
// 所以s就代表的是流中的每一个数据
// 我们只要在accept方法中对数据做业务逻辑处理即可
list.stream().forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("=====================");
list.stream().forEach( (String s) -> {
System.out.println(s);
});
System.out.println("=====================");
list.stream().forEach( s -> { System.out.println(s); });
}
}
2.6 Stream流中的收集方法
- 在Stream流中无法直接修改集合,数组等数据源中的数据。
- Stream流的收集方法
- R collect(Collector collector) : 此方法只负责收集流中的数据 , 创建集合添加数据动作需要依赖于参数
- 工具类Collectors提供了具体的收集方式
- public static <T> Collector toList():把元素收集到List集合中
- public static <T> Collector toSet():把元素收集到Set集合中
- public static Collector toMap(Function keyMapper,Function valueMapper):把元素收集到Map集合中
/*
定义一个集合,并添加一些整数1,2,3,4,5,6,7,8,9,10
将集合中的奇数删除,只保留偶数。
遍历集合得到2,4,6,8,10
*/
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
list.add(i);
}
list.add(10);
list.add(10);
list.add(10);
list.add(10);
list.add(10);
// collect只负责收集流中的数据
// Collectors.toList()会负责在底层创建list集合 ,并把数据添加到集合中 , 返回集合对象
List<Integer> list2 = list.stream().filter(num -> num % 2 == 0 ).collect(Collectors.toList());
System.out.println(list2);
Set<Integer> set = list.stream().filter(num -> num % 2 == 0 ).collect(Collectors.toSet());
System.out.println(set);
}
}
/*
1 创建一个ArrayList集合,并添加以下字符串。字符串中前面是姓名,后面是年龄
"zhangsan,23"
"lisi,24"
"wangwu,25"
2 保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
收集方法 :
public static Collector toMap(Function keyMapper , Function valueMapper):把元素收集到Map集合中
*/
public class StreamDemo7 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("zhangsan,23");
list.add("lisi,24");
list.add("wangwu,25");
// collect 只负责收集数据
// Collectors.toMap负责在底层创建集合对象 , 添加元素
// toMap方法中的s就是代表的是集合中的每一个元素
// 第一个参数 : 如何获取map集合中的键
// 第二个参数 : 如何获取map集合中的值
Map<String, String> map = list.stream().filter(s -> Integer.parseInt(s.split(",")[1]) > 23).collect(
Collectors.toMap(
(String s) -> {
return s.split(",")[0];
}
,
(String s) -> {
return s.split(",")[1];
}
)
);
System.out.println(map);
}
}
2.7 其它
@Test
public void test01(){
HashMap<String, String> hm = new HashMap<>();
hm.put("11", "曹植");
hm.put("22", "曹丕");
hm.put("33", "曹熊");
hm.put("44", "曹冲");
hm.put("55", "曹昂");
//将map中的键转换成int类型,封装到集合下
//Set<Integer> intSet = hm.keySet().stream().map(keyStr -> {return Integer.valueOf(keyStr);}).collect(Collectors.toSet());
Set<Integer> intSet = hm.keySet().stream().map(keyStr -> Integer.valueOf(keyStr)).collect(Collectors.toSet());
System.out.println(intSet);
//将map中的键转化成int类,并获取一个等于22的值(出现多个,则任意获取一个)
Optional<Integer> first = hm.keySet().stream().map(keyStr -> Integer.valueOf(keyStr)).filter(num -> num == 22).findFirst();
//判断是否存在
if (first.isPresent()) {
System.out.println(first.get());
}else {
System.out.println("数据不存在");
}
Optional<Integer> any = hm.keySet().stream().map(keyStr -> Integer.valueOf(keyStr)).filter(num -> num == 22).findAny();
if (any.isPresent()) {
System.out.println(any.get());
}
//注意:在串行的流中,findAny和findFirst返回的,都是第一个对象;而在并行的流中,findAny返回的是最快处理完的那个线程的数据
}
三、File类
3.1 File类的介绍
- java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作
3.2 构造方法
/*
File:它是文件和目录路径名的抽象表示
文件和目录可以通过File封装成对象
File封装的对象仅仅是一个路径名。它可以是存在的,也可以是不存在的。
构造方法 :
1 File(String pathname) 通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例
2 File(String parent, String child) 从父路径名字符串和子路径名字符串创建新的 File实例
3 File(File parent, String child) 从父抽象路径名和子路径名字符串创建新的 File实例
*/
public class FileDemo1 {
public static void main(String[] args) {
// 1 File(String pathname) 通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例
File f1 = new File("D:\\abc.txt");
System.out.println(f1);
// 2 File(String parent, String child) 从父路径名字符串和子路径名字符串创建新的 File实例
File f2 = new File("D:\\aaa", "bbb.txt");
System.out.println(f2);
// 3 File(File parent, String child) 从父抽象路径名和子路径名字符串创建新的 File实例
File f3 = new File(new File("D:\\aaa"), "bbb.txt");
System.out.println(f3);
}
}
3.3 File类的创建功能
/*
File类的创建功能 :
1 public boolean createNewFile() : 创建一个新的空的文件
2 public boolean mkdir() : 创建一个单级文件夹
3 public boolean mkdirs() : 创建一个多级文件夹
*/
public class FileDemo2 {
public static void main(String[] args) throws IOException {
File f1 = new File("D:\\a.txt");
// 1 public boolean createNewFile() : 创建一个新的空的文件
System.out.println(f1.createNewFile());
File f2 = new File("day10_demo\\aaa");
// 2 public boolean mkdir() : 创建一个单级文件夹
System.out.println(f2.mkdir());
File f3 = new File("day10_demo\\bbb\\ccc");
// 3 public boolean mkdirs() : 创建一个多级文件夹
System.out.println(f3.mkdirs());
}
}
3.4 File类的删除功能
/*
File类删除功能 :
public boolean delete() 删除由此抽象路径名表示的文件或目录
注意 :
1 delete方法直接删除不走回收站。
2 如果删除的是一个文件,直接删除。
3 如果删除的是一个文件夹,需要先删除文件夹中的内容,最后才能删除文件夹
*/
public class FileDemo3 {
public static void main(String[] args) throws IOException {
File f1 = new File("D:\\a.txt");
// 1 public boolean createNewFile() : 创建一个新的空的文件
System.out.println(f1.delete());
File f2 = new File("day10_demo\\aaa");
// 2 public boolean mkdir() : 创建一个单级文件夹
System.out.println(f2.delete());
File f3 = new File("day10_demo\\bbb");
// 3 public boolean mkdirs() : 创建一个多级文件夹
System.out.println(f3.delete());
}
}
3.5 File类的判断和获取功能
/*
File类判断和获取功能
public boolean isDirectory() 测试此抽象路径名表示的File是否为目录
public boolean isFile() 测试此抽象路径名表示的File是否为文件
public boolean exists() 测试此抽象路径名表示的File是否存在
public String getAbsolutePath() 返回此抽象路径名的绝对路径名字符串
public String getPath() 将此抽象路径名转换为路径名字符串
public String getName() 返回由此抽象路径名表示的文件或目录的名称
*/
public class FileDemo4 {
public static void main(String[] args) {
File f1 = new File("day10_demo\\aaa");
File f2 = new File("day10_demo\\a.txt");
// public boolean isDirectory() 测试此抽象路径名表示的File是否为目录
System.out.println(f1.isDirectory());
System.out.println(f2.isDirectory());
// public boolean isFile() 测试此抽象路径名表示的File是否为文件
System.out.println(f1.isFile());
System.out.println(f2.isFile());
// public boolean exists() 测试此抽象路径名表示的File是否存在
System.out.println(f1.exists());
// public String getAbsolutePath() 返回此抽象路径名的绝对路径名字符串
System.out.println(f1.getAbsolutePath());
// public String getPath() 将此抽象路径名转换为路径名字符串
System.out.println(f1.getPath());
// public String getName() 返回由此抽象路径名表示的文件或目录的名称
System.out.println(f2.getName());
}
}
3.6 File类高级获取功能
/*
File类高级获取功能
public File[] listFiles() 返回此抽象路径名表示的目录中的文件和目录的File对象数组
listFiles方法注意事项:
1 当调用者不存在时,返回null
2 当调用者是一个文件时,返回null
3 当调用者是一个空文件夹时,返回一个长度为0的数组
4 当调用者是一个有内容的文件夹时,将里面所有文件和文件夹的路径放在File数组中返回
5 当调用者是一个有隐藏文件的文件夹时,将里面所有文件和文件夹的路径放在File数组中返回,包含隐藏内容
*/
public class FileDemo5 {
public static void main(String[] args) {
File file = new File("day10_demo\\bbb\\ccc");
// 返回此抽象路径名表示的目录中的文件和目录的File对象数组
File[] files = file.listFiles();
// 遍历File类的数组
for (File f : files) {
// 拿到每一个文件的文字
System.out.println(f.getName());
}
}
}
练习 :
package com.itheima.file_demo;
import java.io.File;
import java.util.HashMap;
/*
练习二 :统计一个文件夹中每种文件的个数并打印。
打印格式如下:
txt:3个
doc:4个
jpg:6个
…
*/
public class FileTest2 {
public static void main(String[] args) {
File file = new File("day10_demo\\统计文件个数文件夹");
getFileCount(file);
}
public static void getFileCount(File f) {
HashMap<String, Integer> hm = new HashMap<>();
// 是文件夹在获取所有的子文件
if (f.isDirectory()) {
File[] files = f.listFiles();
// 遍历数组
for (File file : files) {
String fileName = file.getName();
String name = fileName.split("\\.")[1];
if (hm.containsKey(name)) {
hm.put(name, hm.get(name));
} else {
hm.put(name, 1);
}
}
}
System.out.println(hm);
}
}